The Potential of Multi-Core and Parallel Computing to Unlock Performance
Uncategorized Uncategorized
The Potential of Multi-Core and Parallel Computing to Unlock Performance
In the beginning…
The desire for increasing performance and processing power has been a driving force behind technical developments in the ever-changing world of computing. This demand has become a driving factor behind technological advancements. The implementation of multi-core and parallel computing architectures is one of the most important techniques that has been utilized to satisfy this need. This change is a paradigmatic break from the standard sequential processing model. It promises a jump in computing capabilities that can revolutionize how we tackle difficult tasks. Moreover, this shift constitutes a fundamental departure from the old sequential processing model. In this piece, we will go into the principles of multi-core and parallel computing, investigating their relevance as well as their architecture and applications in the real world.
Comprehending the Concept of Multi-Core Computing:
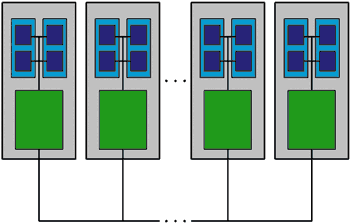
Multi-core computing, at its most fundamental level, refers to the practice of integrating numerous processing units, also known as cores, onto a single chip. This divergence from the conventional concept of a single-core processor enables the simultaneous execution of numerous tasks, which significantly improves the performance of the system as a whole. Parallel processing and the simultaneous execution of multiple instructions are made possible by the fact that each core acts autonomously and possesses its own cache and control unit.
The Need for Parallelism The need for quicker calculation surpassed the capabilities of single-core processors to keep up, which resulted in the need for faster computation. This resulted in the need for parallelism. Computing in parallel, which draws on the capabilities of several processor cores to carry out instruction execution in parallel, has emerged as a viable method for overcoming this constraint. In its most basic form, parallelism is the ability to break down large, difficult processes into more manageable components that may then be worked on simultaneously, therefore drastically cutting the amount of time required to complete the entire process.
Architectures that Run in Parallel:
The division of tasks and the order in which they are carried out may be used to categorize parallel computing into a number of distinct architectures. The task parallelism and the data parallelism architectural styles are both rather widespread. Data parallelism focuses on dividing the same job across several cores, each of which is operating on various sets of data, whereas task parallelism includes simultaneously executing different tasks on separate cores. job parallelism is also known as task multitasking.
In addition, parallel architectures may be divided into two groups: those that use symmetric multiprocessing (SMP) and those that use massively parallel processing (MPP). SMP refers to a configuration in which many identical processors collaborate on the completion of separate tasks while sharing a memory space. MPP, on the other hand, is distinguished by the presence of a large number of processors that operate in parallel and are often connected by a high-speed interface. As a result, it is well-suited for the management of complicated calculations and enormous datasets.
Applications in the Real World:
The influence of multi-core and parallel computing may be seen in a number of different spheres, ranging from scientific research to applications used in daily life. Parallel computing enables researchers to solve difficult issues in scientific simulations and modeling, such as climate modeling, molecular dynamics, and fluid dynamics. This is accomplished by splitting the computational effort across numerous cores on a single computer.
In the fields of artificial intelligence and machine learning, parallel processing helps to speed up the process of training complex models, which in turn enables more rapid decision-making and more precise forecasting. This is especially important since the size and complexity of datasets in these domains continue to expand at a rapid rate.
The processing needs of high-definition material involve the simultaneous execution of a large number of computational processes, which is another area in which parallel computing plays an essential role. This includes the rendering and editing of videos. In addition, sectors including the financial industry, healthcare, and cybersecurity may all reap the benefits of parallel computing thanks to its capacity to analyze massive datasets, improve algorithm performance, and boost total system output.
Concerns and Things to Take Into Account:
The use of multi-core processors and parallel processing presents a number of problems, despite the fact that the benefits of doing so are enormous. Due to the fact that not all jobs can be readily broken down into parallel subtasks, one of the most important challenges is the necessity for efficient parallelization of algorithms. In order for developers to reap the performance advantages that were promised, careful algorithm design that is capable of fully exploiting the capabilities of multi-core architectures is required.
The management of shared resources, such as memory, should also be taken into mind in order to avoid conflicts and provide the best possible performance. For this purpose, advanced programming approaches and tools are required, which are able to coordinate the actions of numerous cores and control the consistency of the data.
Models and Tools of Programming for Multi-Core and Parallel Computing:
In order for developers to take full use of the power offered by multi-core and parallel architectures, they require programming models and tools that make it possible for them to design and execute efficient parallel algorithms. The creation of parallel applications has been significantly easier because to the development of a number of programming models, each of which has its own set of advantages and is best suited to address specific categories of issues.
Model of Programming with Shared Memory The shared memory programming model is a common method to parallel programming. In this model, many cores have access to a memory space that is shared by all of them. Because the cores may read and write to the same locations in shared memory, this paradigm makes it much easier for them to communicate with one another and share data. For shared memory parallel programming, the OpenMP (Open Multi-Processing) Application Programming Interface (API) is the industry standard. It does this by providing directives that let developers to declare parallel sections in their code, so dividing the burden among all of the available cores.
. .
Model of Programming Based on Message Passing: The message passing paradigm, on the other hand, includes communicating across distinct processes by using message passing interfaces (MPI). Each process has its own memory area, and the only way for processes to communicate with one another is via sending messages back and forth. High-performance computing (HPC) settings and large-scale cluster systems often make heavy use of the Message Passing Interface, or MPI. It makes it possible to construct scalable and effective parallel programs, which is particularly useful for resolving issues that involve coordinating the activities of several distributed components.
. .
Data parallelism and single instruction multiple data (SIMD): Data parallelism is a programming paradigm in which the same operation is executed to many sets of data in parallel. SIMD stands for single instruction multiple data. Architectures known as Single Instruction, several Data (SIMD) provide data parallelism at the hardware level by simultaneously executing the same instruction on several data pieces. SIMD instructions are supported by current processors, and programming frameworks such as Intel’s SIMD-oriented Extensions (SSE) and Advanced Vector Extensions (AVX) allow developers to harness data parallelism for performance advantages in applications such as image processing and scientific computing……………………
Task Parallelism: Task parallelism focuses on splitting a program into individual tasks that may be run in parallel with one another. Tasks can be independent of one another. This paradigm works very effectively for applications that have workloads that are irregular or constantly changing. Abstractions for task parallelism are provided by frameworks like Intel Threading Building Blocks (TBB) and Microsoft’s Parallel Patterns Library (PPL). These abstractions enable developers to express parallelism at a higher level, frequently without diving into low-level specifics.
Computing on a Graphics Processing Unit (GPU) Because of their highly parallel design, Graphics Processing Units (GPUs) have become more popular for parallel computing. The General-Purpose Graphics Processing Unit, often known as GPGPU computing, enables developers to offload parallelizable work to the GPU, which substantially speeds up calculations. CUDA, which stands for “Compute Unified Device Architecture,” and OpenCL, which stands for “Open Computing Language,” are both programming models for GPU computing. These models offer a platform-independent method to take use of the parallel processing capabilities of GPUs.
Problems Associated with Parallel Programming: Parallel programming presents a number of obstacles for developers, despite the fact that it has the potential to improve performance. The possibility of race situations and data dependencies, both of which can result in unexpected behavior and mistakes, is one of the main challenges that must be overcome. To guarantee that there is adequate coordination between activities that are being performed in parallel, synchronization methods like locks and barriers need to be properly implemented.
In addition, load balancing is an essential component in order to make the most of the potential of parallel applications. It is possible for there to be underutilization of resources due to uneven workloads across cores, which would render the benefits of parallelism null and void. It is necessary for developers to create dynamic load balancing algorithms in order to efficiently distribute work and prevent cores from idle while other cores are still processing jobs.
Finding and fixing bugs in parallel programs is fundamentally more difficult than finding and fixing bugs in sequential programs. Specialized debugging tools are required in order to locate and diagnose problems associated with parallelism. Some examples of these problems are race situations and deadlocks. Fortunately, tools like as Intel Inspector and TotalView give useful insights into the behavior of parallel programs, which assists developers in swiftly detecting and resolving difficulties.
Looking to the Future: The Prospects for the Future of Computing in Parallel: Parallelism is without a doubt where computing will be headed in the future as technology continues to make strides forward. The transition toward heterogeneous architectures, which combine conventional central processing units (CPUs) with accelerators such as graphics processing units (GPUs), is becoming an increasingly widespread practice. In addition, developments in hardware design, programming paradigms, and tool development will further democratize the use of parallel computing, making it more accessible to developers working in a variety of fields and industries.
In the following section of this article, we will investigate the hardware advancements that are driving the evolution of multi-core processors. More specifically, we will investigate how innovations such as simultaneous multithreading (SMT) and cache coherence protocols contribute to the effectiveness and scalability of parallel computing architectures.
Recent Developments in Multi-Core Processor Technology:
Continuous developments that attempt to improve performance, scalability, and efficiency have been a hallmark of the development of multi-core processors over the course of their history. Simultaneous Multithreading, or SMT for short, is a method that has become an essential component of current processors. SMT is a technology that enables many threads to run simultaneously on a single core. SMT improves overall throughput and responsiveness by increasing core usage by allowing several threads to share the same execution resources.
One further essential component of multi-core CPUs is something called cache coherence protocols. When there are more cores in a computer, it is more important than ever to have effective management of the shared cache in order to avoid data inconsistencies and conflicts. Maintaining cache coherence requires the use of protocols such as MESI (Modified, Exclusive, Shared, Invalid) and MOESI (Modified, Owned, Exclusive, Shared, Invalid), which ensure that all cores have an identical perspective on shared data.
In addition, developments in on-chip interconnect technology play a crucial part in the process of making communication between cores easier to accomplish. High-speed interconnects like Intel’s QuickPath Interconnect (QPI) and AMD’s Infinity Fabric help to improve the overall performance of multi-core systems by lowering the amount of delay that occurs during data transfers and making it possible for more efficient data exchanges.
Architectures with Heterogeneous Components:
The integration of different kinds of computer architectures will have an increasingly significant impact on the development of parallel computing in the future. An approach to parallelism that is synergistic can be achieved by combining many distinct types of processing units, such as general-purpose central processing units (CPUs) and specialized accelerators, such as graphics processing units (GPUs). This tendency is particularly apparent in the field of high-performance computing (HPC) and artificial intelligence (AI), where workloads frequently display various characteristics that may be better addressed by specialist hardware. Specifically, the term “workloads” refers to the data being processed by a computer system.
The use of heterogeneous architectures gives programmers the ability to capitalize on the advantages offered by each individual processing unit, so striking a healthy balance between general-purpose and specialized computing. Frameworks for programming heterogeneous systems may be found on platforms like as NVIDIA’s CUDA and AMD’s ROCm. These platforms allow developers to take advantage of the parallel processing capabilities of GPUs in conjunction with the capabilities of standard CPUs.
The Increasing Popularity of Quantum Computing:
The introduction of quantum computing provides a paradigm change that promises exponential advances in processing power. While multi-core and parallel computing have pushed the bounds of conventional computing, the arrival of quantum computing introduces this shift. The laws of quantum physics are utilized by quantum computers in order to carry out calculations by utilizing qubits, which are capable of being in numerous states at the same time.
Through the use of quantum parallelism, quantum computers are able to handle huge quantities of information in parallel, which might lead to the solution of complicated problems that are now unsolvable using classical computers. The field of quantum computing, on the other hand, is still in its nascent phases of development and faces a number of hurdles, including error correction and qubit stability. Quantum computing has the potential to transform some aspects of computing as the technology progresses, notably in the areas of optimization, cryptography, and simulation.
Concluding remarks: Accepting the Existence of the Parallelism Era:
A B. Tech in computer science engineering is a wise decision if you want to shape your future and
improve yourself. In addition to AI and data science, the Internet of Things, and bioinformatics, CSE has
a lot more for you to study. It alsoIn conclusion, the era of parallel computing has arrived, which will drive innovations that redefine the bounds of what is possible with regard to computational capabilities. This revolution is being led by multi-core processors, parallel programming paradigms, and heterogeneous architectures, all of which are at the vanguard and provide developers with the ability to unlock previously unattainable levels of performance.
The relevance of parallel computing is becoming more and more apparent as we continue to face more difficult challenges in areas like as scientific research, artificial intelligence, and data analytics. Not only does the partnership between advances in hardware and complex programming models meet the present need for speed and efficiency, but it also enables us to meet the challenges and seize the possibilities that lie ahead.
In this article’s concluding portion, we will investigate real-world case studies that demonstrate the revolutionary impact of multi-core and parallel computing. These case studies will highlight the practical significance and far-reaching ramifications of adopting parallelism in the quest of computing excellence. From ground-breaking scientific discoveries to revolutionary breakthroughs in industry, these case studies will demonstrate how parallelism has been instrumental in achieving both.
Multi-core computing and parallel computing both represent a major leap in the field of computing since they offer processing power and performance that have never been seen before. The need for processing that is both quicker and more efficient is expected to continue to rise, and as a result, the utilization of parallel architectures is expected to become increasingly widespread across a variety of business sectors. In the next sections of this article, we are going to go deeper into the programming models and tools that are used in multi-core and parallel computing. Specifically, we are going to investigate the strategies that enable developers to harness the full power of these architectures.
offers you a wide range of electives to pick from, giving you the
opportunity to explore a variety of job prospects in top-ranking industries with high incomes.

Related Posts

Revolutionizing Higher Education: The Future of Learning – Geeta University
Revolutionizing Higher Education: The Future of Learning – Geeta University Higher education is experiencing a profound transformation, driven by advancements in technology and changing student needs. The future of learning is marked by innovation, collaboration, and personalized experiences. In this
Competency-Based Education
Competency-based education (CBE) is a teaching-learning approach that enables students to learn according to their capacity to acquire knowledge or skills at their own speed, regardless of the setting. This approach supports a variety of learning styles and learning goals

The Importance of Sustainable Practices in the Hospitality Industry
In recent years, sustainability has become a key focus in the hospitality industry. As the world grapples with environmental challenges and consumers become more environmentally conscious, businesses in the hospitality sector are increasingly recognizing the importance of integrating sustainable practices